



|
Philosophy instructor, recreational writer, humorless vegetarian.
|

Saint Paul, MN, USA

2 public comments

Innovative! 🚀
tbd

Most coffee shops have a descendant of Sophia of Hanover on staff for this, but just as I was about to ask for help, a previously unknown heir of Uther Pendragon who was ordering a muffin tripped on my laptop cord.
These have to be some of the most remarkable sports photos of all time: a 20-year-old Lionel Messi bathing a five-month-old Lamine Yamal.



Two of the best football players in the world, one a Barcelona legend and another a Barca legend in the making. Both came up through the ranks of the club’s La Masia youth academy. Both wore number 19 for Barca before switching to the number 10. And if Argentina can advance past England in this afternoon’s semifinal match, the two will face each other in the World Cup final on Sunday. It’s like if there was a photo of Muhammad Ali holding Mike Tyson as a baby. Remarkable.
And the way the photos happened is completely random; Yamal’s family didn’t have footballing connections or anything like that. The photos were taken by photographer Joan Monfort in 2007 for a UNICEF fundraiser (UNICEF was the jersey “sponsor” for Barca’s 2007-2008 season).
“UNICEF did a raffle in the neighbourhood of Roca Fonda in Mataro where Lamine’s family lived,” said Monfort. “They signed up for the raffle to have their picture taken at the Camp Nou with a Barca player. And they won the raffle.”
“He [Messi] didn’t even know how to hold him at first,” Monfort said, recalling the difficulties of the shoot. “Messi is a pretty introverted guy, he’s shy. He was coming out of the locker room and suddenly he finds himself in another locker room with a plastic tub full of water and a baby in it. It was complicated.”
More from Monfort in The Athletic:
“It’s the most famous photo I’ve taken in my life, by a long way. So many people have been interested, again during this World Cup now. If Lamine keeps growing like he is growing, the photo will be even more historic. The chances of all this happening was like winning the lottery. Although it’s not sorted me out financially for life (laughs).
“I’m just really happy it happened. It’s especially nice in today’s football, when so much is to do with money and power.”
Tags: Joan Monfort · Lamine Yamal · Lionel Messi · photography · soccer · sports
Saint Paul, MN, USA
A code of principles proposed at the 1889 National Hobo Convention:
- Decide your own life; don’t let another person run or rule you.
- When in town, always respect the local law and officials, and try to be a gentleman at all times.
- Don’t take advantage of someone who is in a vulnerable situation, locals or other hobos.
- Always try to find work, even if temporary, and always seek out jobs nobody wants. By doing so you not only help a business along, but ensure employment should you return to that town again.
- When no employment is available, make your own work by using your added talents at crafts.
- Do not allow yourself to become a stupid drunk and set a bad example for locals’ treatment of other hobos.
- When jungling [camping] in town, respect handouts and do not wear them out; another hobo will be coming along who will need them as badly, if not worse than you.
- Always respect nature; do not leave garbage where you are jungling.
- If in a community jungle, always pitch in and help.
- Try to stay clean, and boil up wherever possible.
- When traveling, ride your train respectfully. Take no personal chances. Cause no problems with operating crew or host railroad. Act like an extra crew member.
- Do not cause problems in a train yard; another hobo will be coming along who will need passage through that yard.
- Do not allow other hobos to molest children; expose all molesters to authorities – they are the worst garbage to infest any society.
- Help all runaway children, and try to induce them to return home.
- Help your fellow hobos whenever and wherever needed; you may need their help someday.
- If present at a hobo court and you have testimony, give it. Whether for or against the accused, your voice counts!
The convention was held by Tourist Union #63, a union of hobos created in the mid-1800s. Members sought to resist anti-vagrancy laws by representing themselves as itinerant workers rather than idle miscreants.

Well, that was interesting.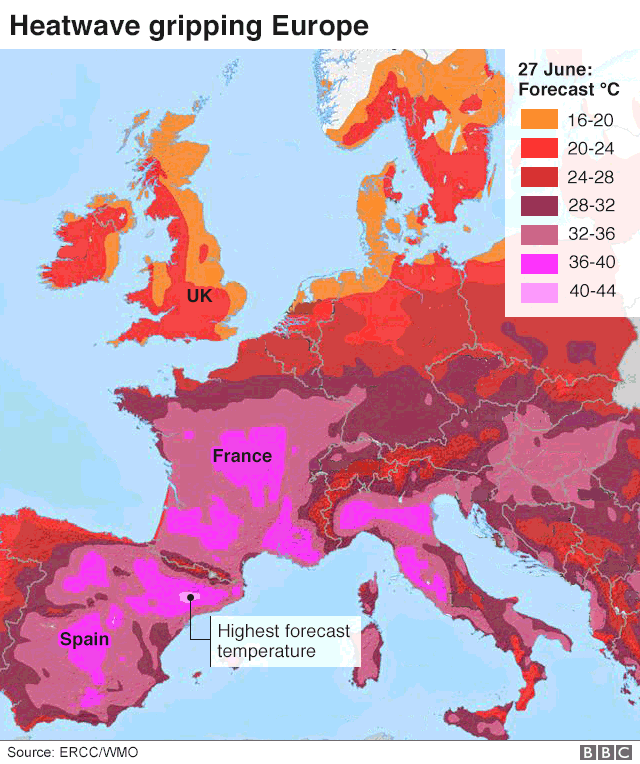

Some quick thoughts below the cut.
So I’ve recently become much more aware of the Discourse about air conditioning that is common to much of northern Europe. There’s a lot of weirdness generally, but there are certain strains that pop up regularly.
One is Left / green concern about emissions. Unlike a lot of Left / green concerns, this one doesn’t stop at hand-wringing. It tends to go straight to moral condemnation and direct action. A surprising lot of northern European greens view aircon as somewhere between “acceptable only in the direst of needs” and “just inherently very wicked”.
Another is a strain of what I can only call machismo. Find an online discussion about aircon, and within a few comments you’ll find the guy — it’s always a guy — who wants you to know that he was with British Forces Arabian Penninsula at Aden back in the day, and nobody had ever heard of this aircon nonsense, and they were just fine, damn your eyes. Or the guy — it’s always a guy — who is living in a house his great-grandfather built with his own two hands, insulated proper-like and with real brass fittings, warm in winter and cool in summer, add a ceiling fan and that’s all a man should ever need.
Related to that last one is Anything But Aircon. You see, if you just install a geothermal heat pump, and get better insulation, and plant trees around the house and ivy on outer walls, and add awnings and external shading, and paint your roof white, and get double- glazed windows with louvers, and a ceiling fan in every room, and fill your living spaces with large house plants, and also sleep with a mattress topper and 100% breathable linen or high-thread-count Egyptian cotton sheets, then you should be completely fine.
Yet another is, not exactly anti-Americanism, but defining-us-against-Americanism. Those huge malls — icy cold, I needed a sweater! Have you heard they have stadiums that are air-conditioned? And ice in their beer!
Apropos of that last point. Here’s a temporal heat map of London:

and one for New York City:
— But NYC has a relatively mild climate by North American standards. Here’s Kansas City:
In Kansas City, nature is actively trying to kill you quite a lot of the time. There’s literally no place in Europe, from Cornwall to the Urals, that has a climate as extreme as Kansas City.
And these are the temperate parts of the USA — the bits where average temperatures are comparable to much of Europe. I’m not even going to bother with maps from Houston or New Orleans or Los Angeles.
Do Americans overuse aircon? Oh yes, we absolutely do. But do we need aircon? Also yes. Most of us do, at least some of the time. There are a couple of corners of the country where it rarely gets that warm — upper New England, a strip along the Pacific coast, the airier bits of the mountain West. But around 80 percent of the US population lives in places where summers without aircon are not just unpleasant, but actively bad for mental and physical health. 99% of homes in Houston have aircon. And if you’ve ever spent a summer in Houston, that statistic will leave you wondering how there can possibly be 1% that don’t.
On the positive side, the US has built about all the aircon it’s going to.
This is very much not the case around the world! Here’s a projection of the growth of aircon worldwide.
Aircon use has roughly doubled in the last 25 years, and it’s set to double again. That has a bit to do with climate change and much more to do with rising income. Over the next 25 years, a couple of billion people in China, India, and Africa are going to get air conditioning.
And, you know, aircon saves hundreds of thousands of lives worldwide every year. Heat stress and dehydration are killers, especially for small children and the elderly. Workers are more efficient with aircon, and children learn better, and hospitals with aircon have better outcomes for the sick and injured. And do you really want to tell the gasping family in Uttar Pradesh, hey, sorry folks but no aircon for you — we have to pull that ladder up behind us, for the good of the planet?
And, you know, aircon saves hundreds of thousands of lives worldwide every year. Heat stress and dehydration are killers, especially for small children and the elderly. Workers are more efficient with aircon, and children learn better, and hospitals with aircon have better outcomes for the sick and injured. And do you really want to tell the gasping family in Uttar Pradesh, hey, sorry folks but no aircon for you — we have to pull that ladder up behind us, for the good of the planet?
Well then, two billion more air conditioning units. How bad is this going to be?
Air conditioning currently causes around 3.6% of greenhouse gas warming. In terms of CO2, it’s a bit less — around 2.7%. But a lot of aircons use refrigerants that are greenhouse gases in their own right, so that bumps the total up.
Looked at one way, aircon produces more emissions than the entire aviation industry. That’s a lot! Looked at another way, we could turn off every air conditioner on the planet tomorrow, and a couple of billion people would be miserable, and hundreds of thousands would die, and there’d be massive economic and social disruption and… we’d reduce emissions by a barely noticeable 3.6%.
That said, more aircon is going to mean more emissions and more warming. So, by selfishly trying to cool ourselves, are we going to cook the planet?
Well… like everything related to climate change, it’s a bit more complicated. For one thing, aircon designs have become dramatically more efficient in recent years. And we’re not even close to the thermodynamic limits, so there’s every reason to think further advances are coming. Current thinking is that increases in efficiency will claw back between a third and half of the increase in electricity demand. So, still not great, but less bad.
Also, electricity in 2050 is going to be, worldwide, a lot less carbonized than it is right now. If you’re running your aircon off solar, wind, hydro, or nuclear, you’re not generating any emissions. And by 2050, hundreds of millions of people will be powering their aircons with low- or no-carbon electricity. Again, still not great, but much less bad than if we added all those aircons today.
And, you know, the folks in Uttar Pradesh and Nanjing and Kinshasa are going to get their aircon. That is, as it were, baked in.
I’ll end with one other fact. I mentioned that aircon produces more emissions than the entire aviation industry. But aircon produces only about a quarter as much emissions as heating. For some reason a lot of people code heating as a necessity of life and aircon as a luxury. Is that objectively correct? I’m not sure.
Anyway. Aircon: it’s complicated.
Air conditioning currently causes around 3.6% of greenhouse gas warming. In terms of CO2, it’s a bit less — around 2.7%. But a lot of aircons use refrigerants that are greenhouse gases in their own right, so that bumps the total up.
Looked at one way, aircon produces more emissions than the entire aviation industry. That’s a lot! Looked at another way, we could turn off every air conditioner on the planet tomorrow, and a couple of billion people would be miserable, and hundreds of thousands would die, and there’d be massive economic and social disruption and… we’d reduce emissions by a barely noticeable 3.6%.
That said, more aircon is going to mean more emissions and more warming. So, by selfishly trying to cool ourselves, are we going to cook the planet?
Well… like everything related to climate change, it’s a bit more complicated. For one thing, aircon designs have become dramatically more efficient in recent years. And we’re not even close to the thermodynamic limits, so there’s every reason to think further advances are coming. Current thinking is that increases in efficiency will claw back between a third and half of the increase in electricity demand. So, still not great, but less bad.
Also, electricity in 2050 is going to be, worldwide, a lot less carbonized than it is right now. If you’re running your aircon off solar, wind, hydro, or nuclear, you’re not generating any emissions. And by 2050, hundreds of millions of people will be powering their aircons with low- or no-carbon electricity. Again, still not great, but much less bad than if we added all those aircons today.
And, you know, the folks in Uttar Pradesh and Nanjing and Kinshasa are going to get their aircon. That is, as it were, baked in.
I’ll end with one other fact. I mentioned that aircon produces more emissions than the entire aviation industry. But aircon produces only about a quarter as much emissions as heating. For some reason a lot of people code heating as a necessity of life and aircon as a luxury. Is that objectively correct? I’m not sure.
Anyway. Aircon: it’s complicated.
Saint Paul, MN, USA
1 public comment
But aircon produces only about a quarter as much emissions as heating. For some reason a lot of people code heating as a necessity of life and aircon as a luxury.
Central Pennsyltucky
Ahead of hosting the championship match, New Yorkers gathered in crowded bars and restaurants, sometimes overflowing onto street corners, to follow the twists and turns of the tournament.
Saint Paul, MN, USA
If Only There Had Been a Sign That the Face-Melting Nazi from Indiana Jones Wouldn’t Make a Good Senator. “Marion Ravenwood said he trapped her in a room and physically assaulted her. But I decided to keep supporting Toht anyway.”
This joke piece does a better job of covering the sordid affair than anything I read in the news. Should be required reading for anyone who excused the Nazi tattoo & the Reddit posts &c on the grounds that ??? is more important than...
Saint Paul, MN, USA
Next Page of Stories